
Research Orientation
I studied Computer Science and Linguistics at the University of Cambridge, completing both my undergraduate and master’s degrees at Gonville & Caius College. Over time, my interests shifted away from formal descriptions of language toward questions of acquisition: how structure arises without explicit instruction, how learning proceeds unevenly, and how competence is gradually assembled rather than suddenly attained.
I am currently supervised by Professor Paula Buttery. My doctoral research examines how grammatical and semantic structure emerges in compact neural systems trained under multilingual and data-limited conditions.
Much of machine learning research is organised around endpoints: benchmarks, leaderboards, final accuracy. My own work is motivated by a discomfort with this framing.
I approach language models instead as epistemic artefacts, focusing on learning dynamics rather than end states, and drawing on tools from psychometrics and developmental psychology—such as item response theory.
Small language models are not merely scaled-down versions of larger ones. Their value lies less in what they achieve than in what they make intelligible.



Language Models: Learning Dynamics and Tokenization
My research is concerned with building data-efficient small Language Models. While industry-led efforts have built competitive LLMs that have fundamentally shifted the job of the contemporary Natural Language Processing (academic) researcher in various ways, there are still several fundamental, open questions to address that are not obviously ancillary to those pursued commercial AI research labs.
For small LMs, tight parameter budgets make each decision critical, yet researchers still lack systematic, scientific ways to test and refine new ideas. We introduce PicoLM, a lightweight, modular framework that enables systematic, hypothesis-driven research for small and medium-scale language model development. Pico consists of two libraries that together provide a practical sandbox where researchers can make targeted changes to a model's architecture or training procedures and directly observe their effects on the model's behaviour. To support reproducible experimentation, we also release a suite of baseline models, trained under standardised conditions and open-sourced for the community. Check out the YouTube Video put together by Zeb Goriely: Introducing PicoLM | YouTube.
Developmental Interpretability (DevInterp) and Language Model Learning Dynamics Research are fundamental to developing small LMs. Small LMs are crucial for low-resourced and democratised Language Modelling, and should still be a serious focus of hypothesis-driven scientific exploration.
Tokenization Publications
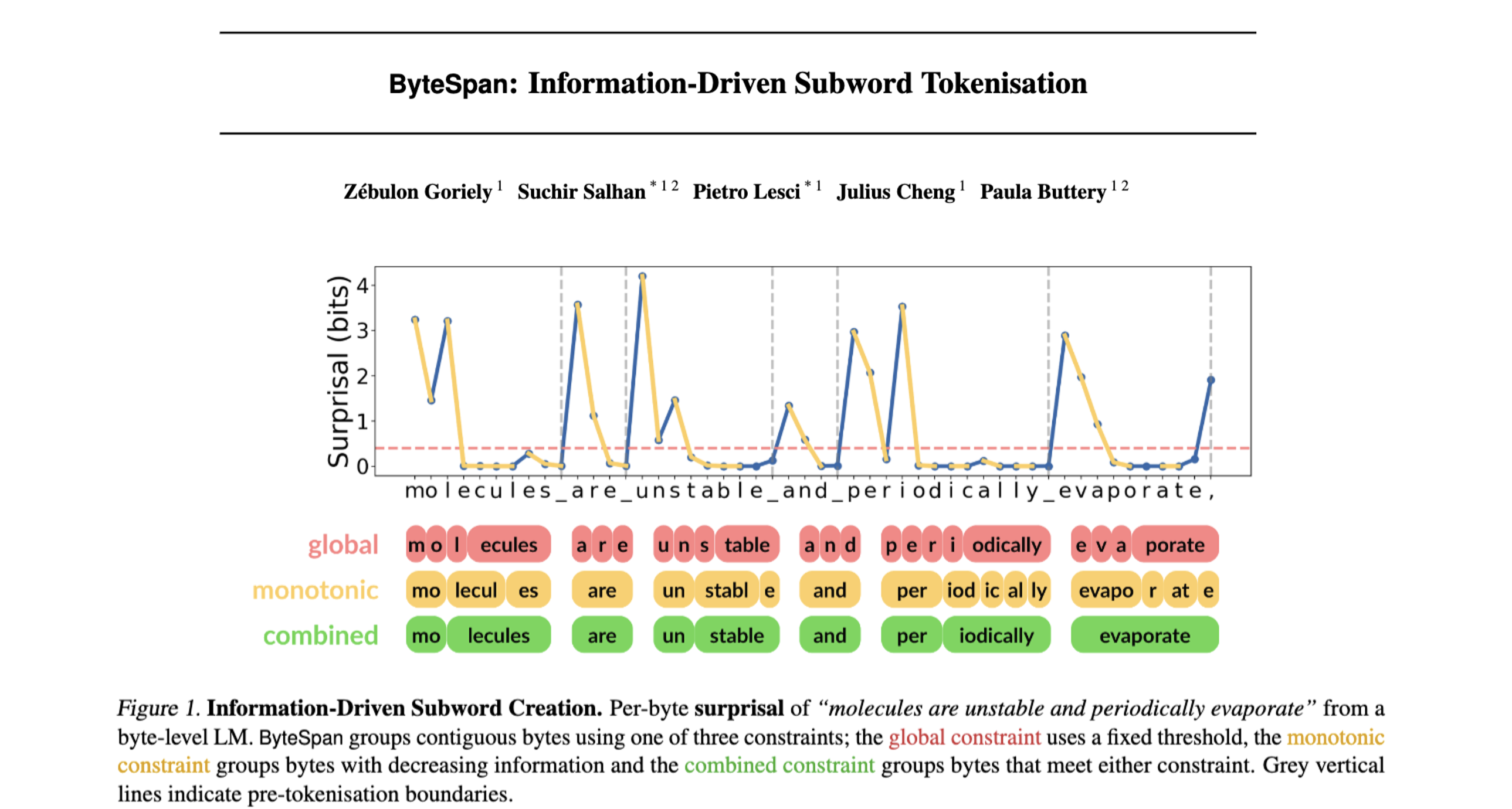
Z Goriely, S Salhan, P Lesci, J Cheng, P Buttery
Cognitively-Inspired AI: Linguistic Interpretability and Multilinguality
The second strand of my research focuses on cognitively-inspired AI. The scientific study of the human capacity for language demands a multi-model approach that combines a characterisation of the universal and language- or speaker-specific substance of grammars and the inductive biases that support their emergence in language acquisition, and how these conditions interact with domain-general cognition. This is why I am, in part, drawn to the work of the BabyLM Workshop.
In joint work, we introduce ByteSpan, a dynamic tokenisation scheme that groups predictable bytes rather than pooling their representations.
BabyLM Publications
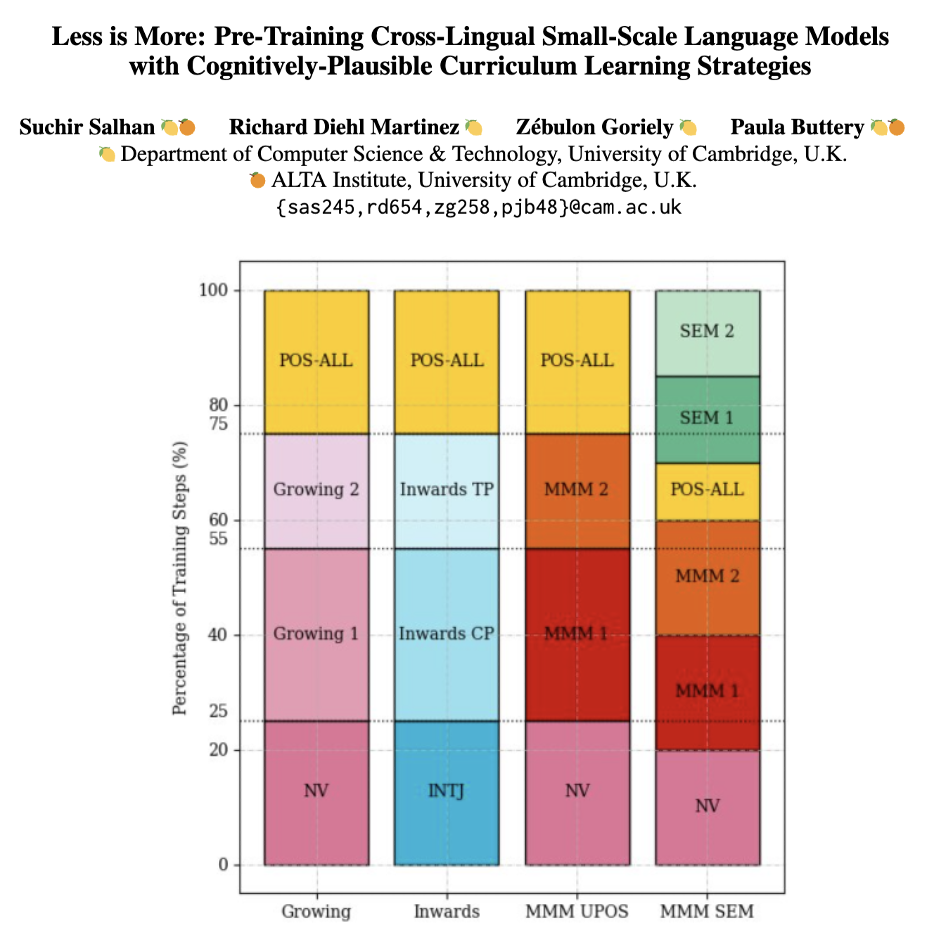
S Salhan, RD Martinez, Z Goriely, P Buttery
Multilingual Publications

DD Africa, S Salhan, Y Weiss, P Buttery, RD Martinez
S Salhan, RD Martinez, Z Goriely, P Buttery
Links
Contact
Email: sas245@cam.ac.uk